moe f&b 计算流程
Router
Router 计算每个 token 应该路由到哪些 expert。
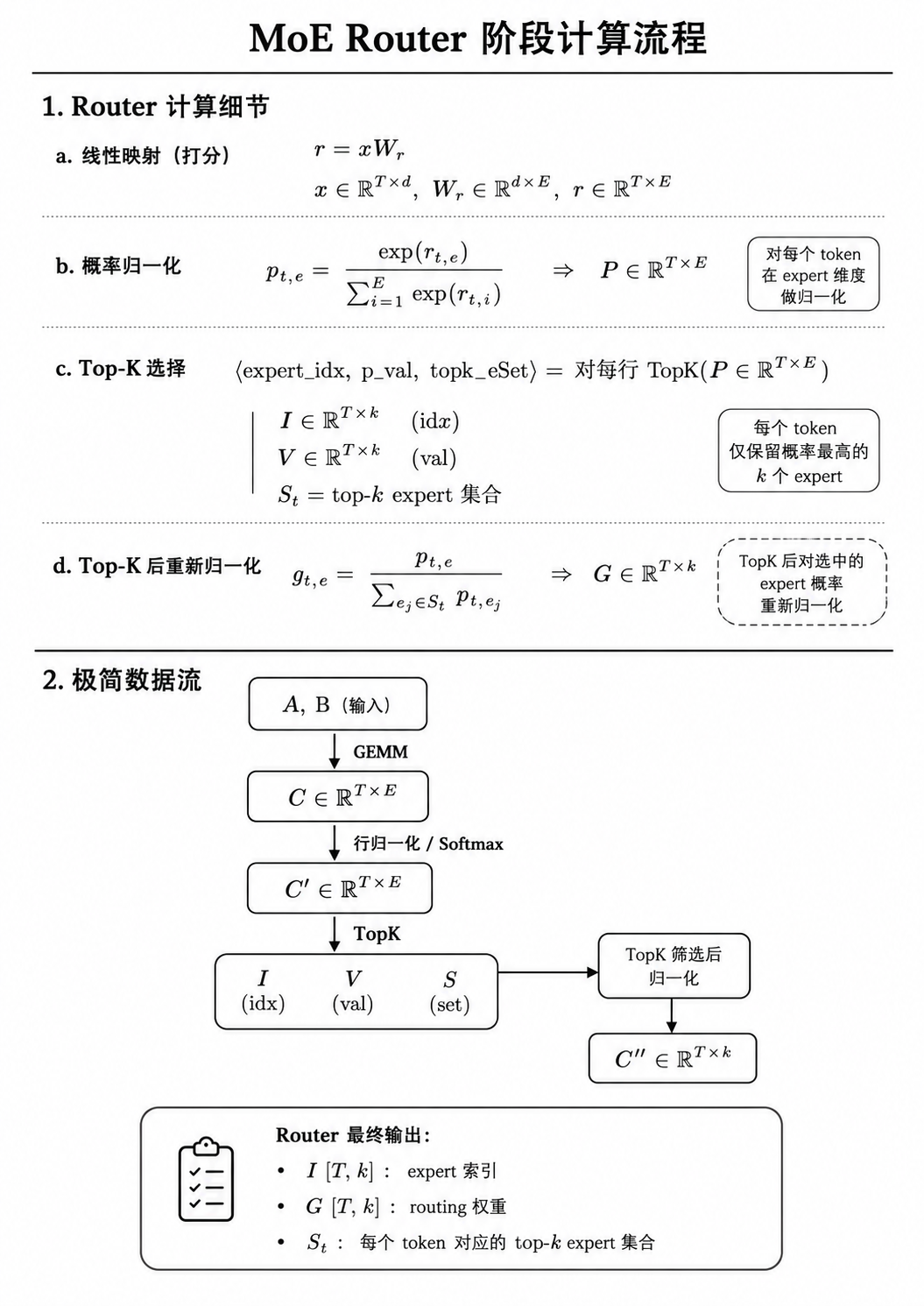
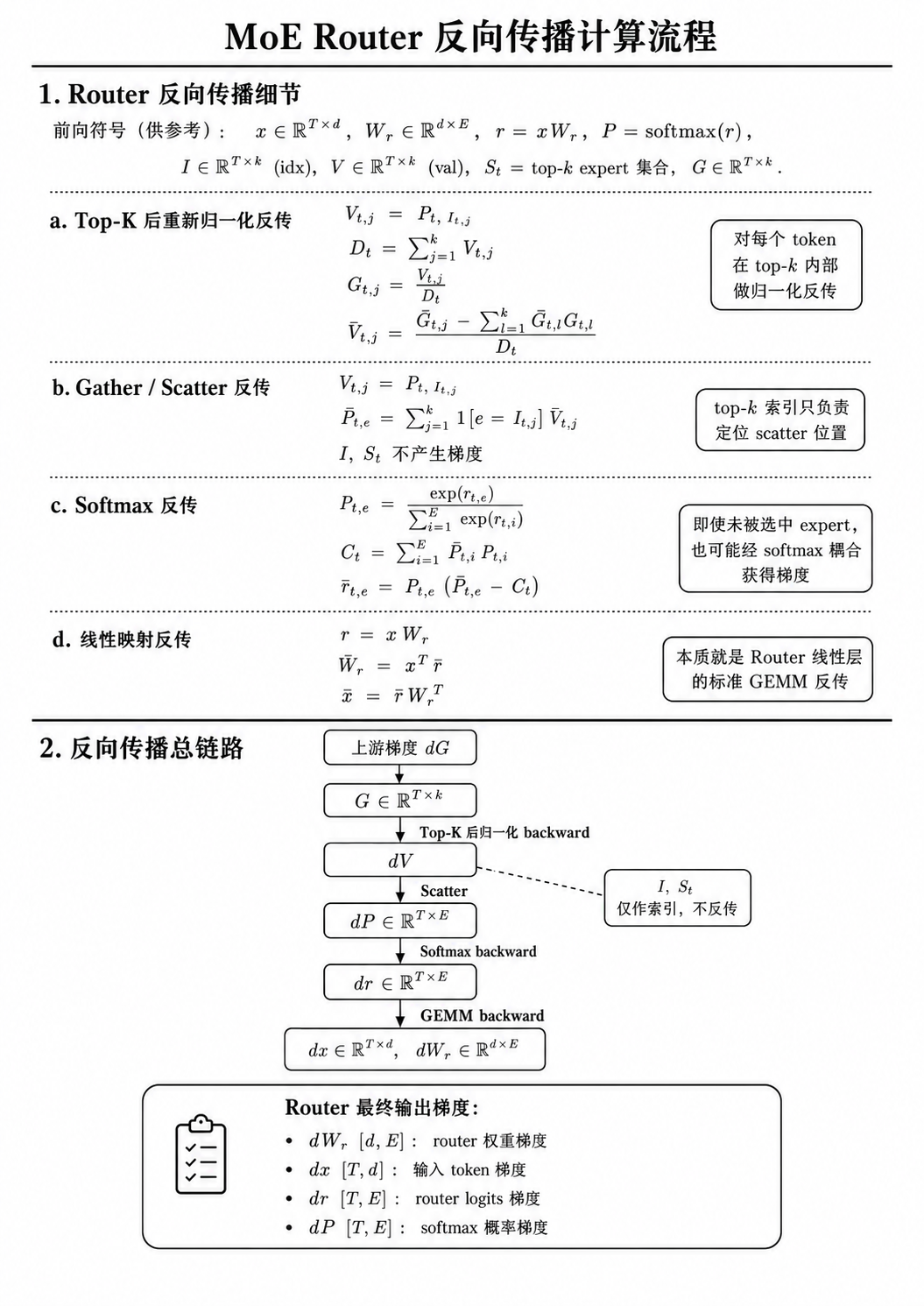
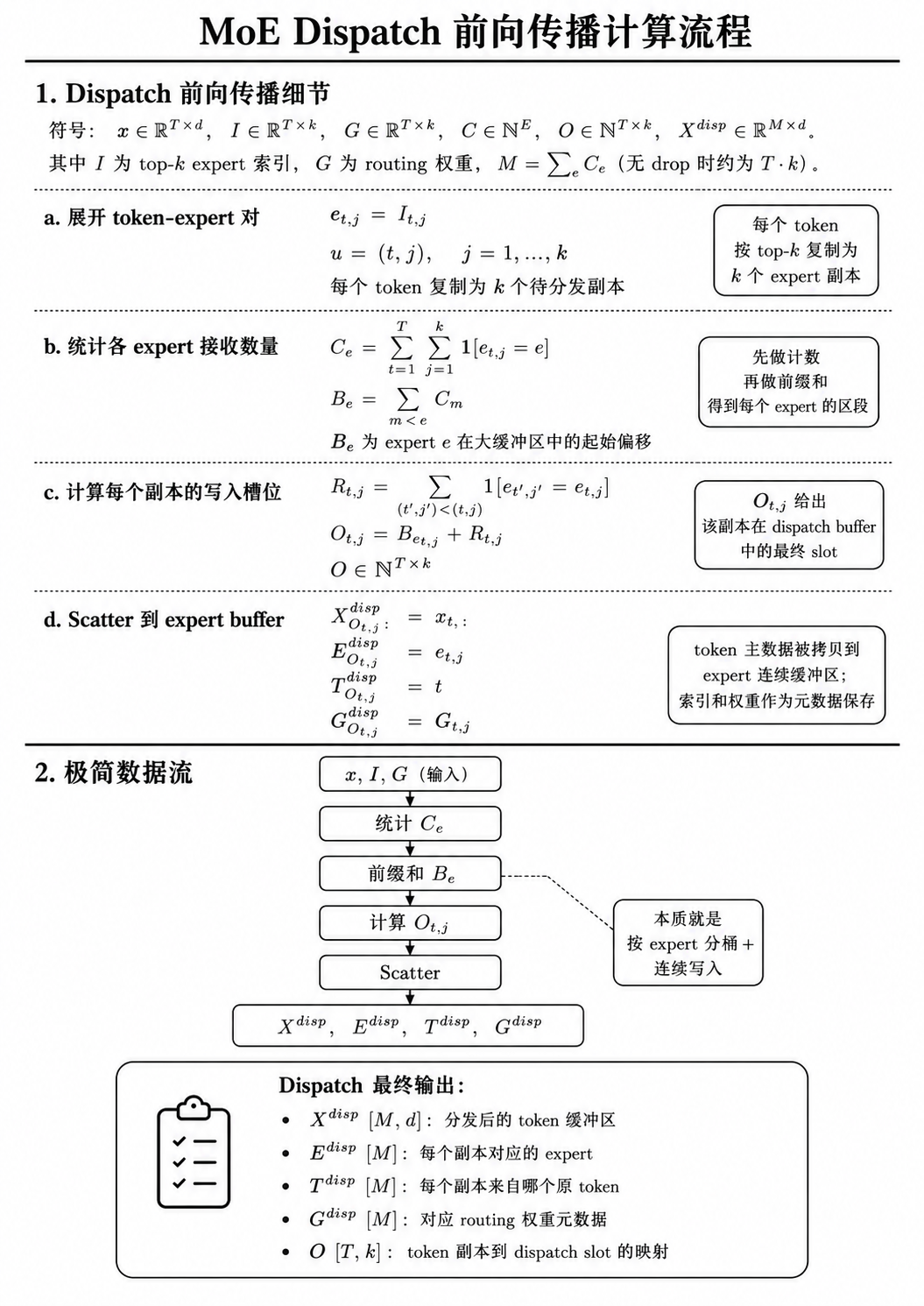
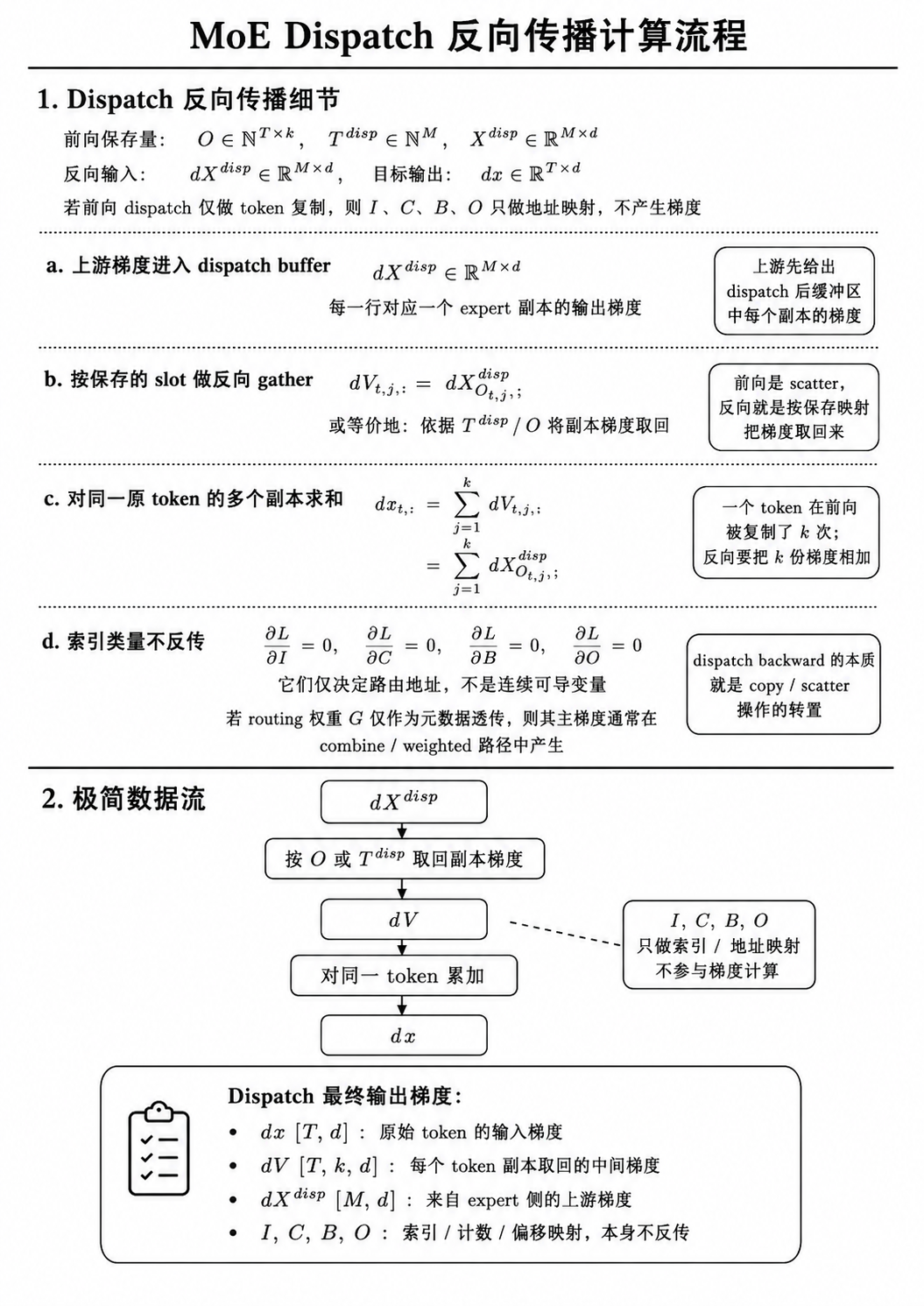
Dispatch
Dispatch 根据 router 结果,把 token 分发到对应 expert 的输入 buffer。
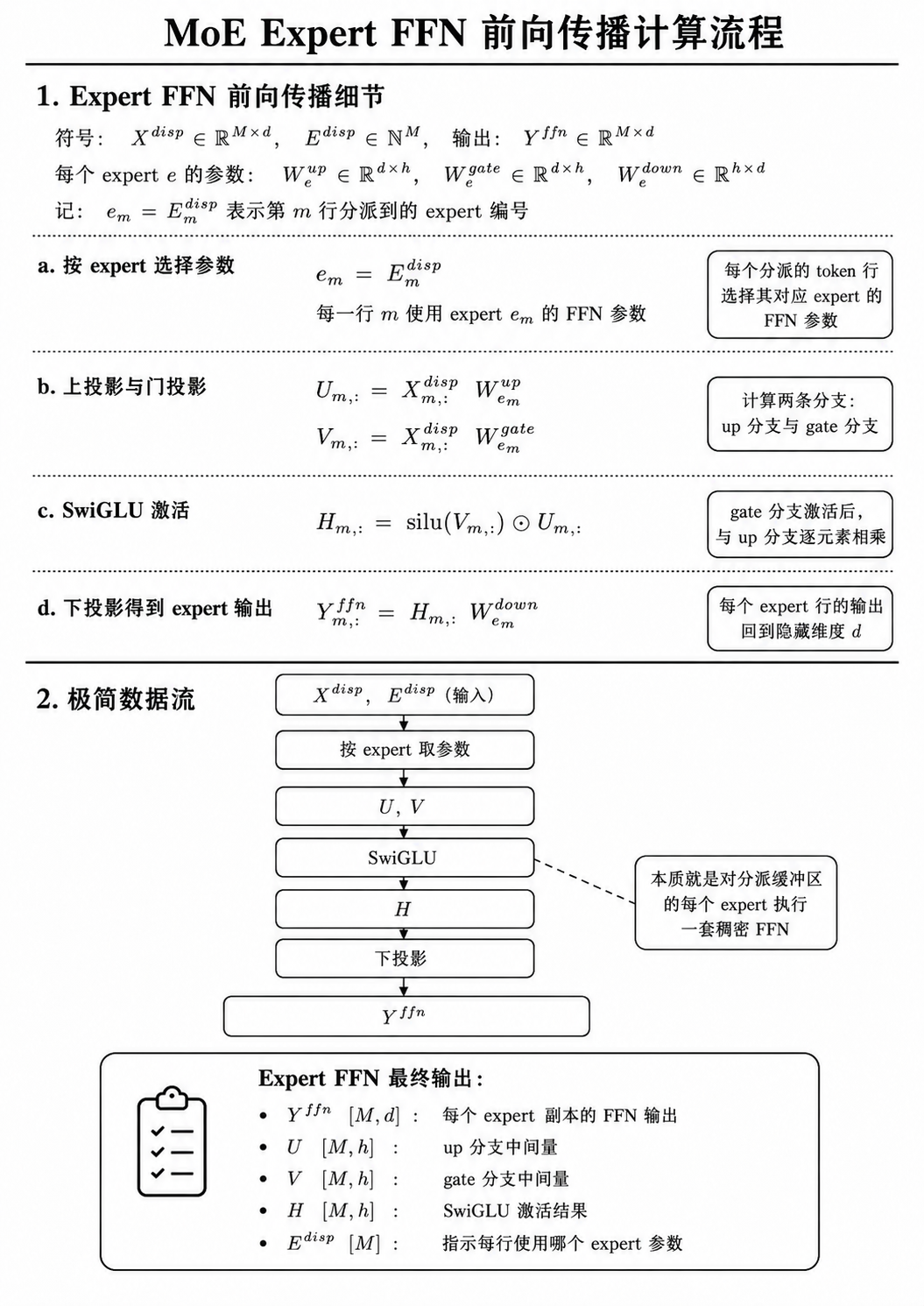
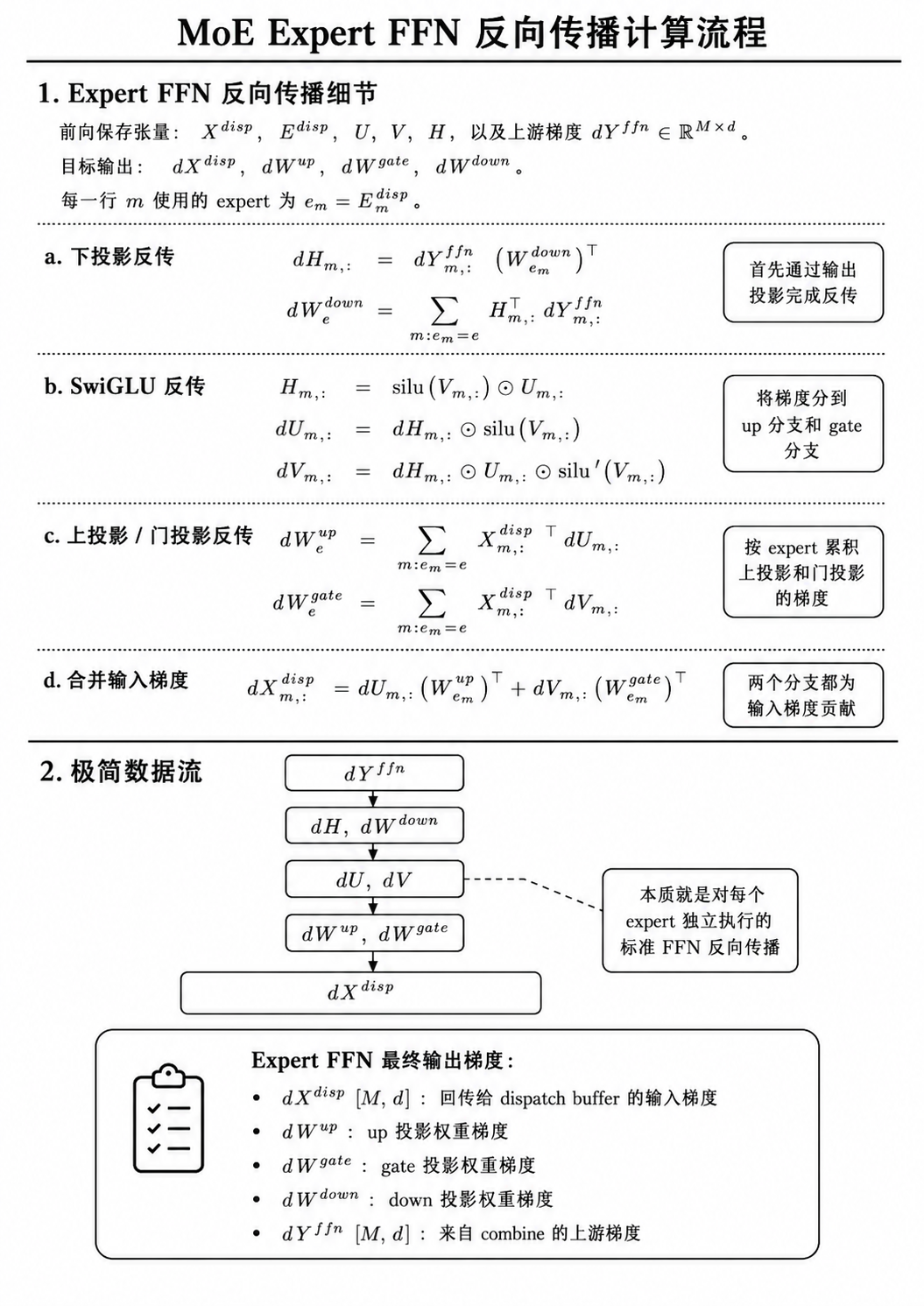
FFN
每个 expert 内部执行自己的 FFN / MLP 计算。
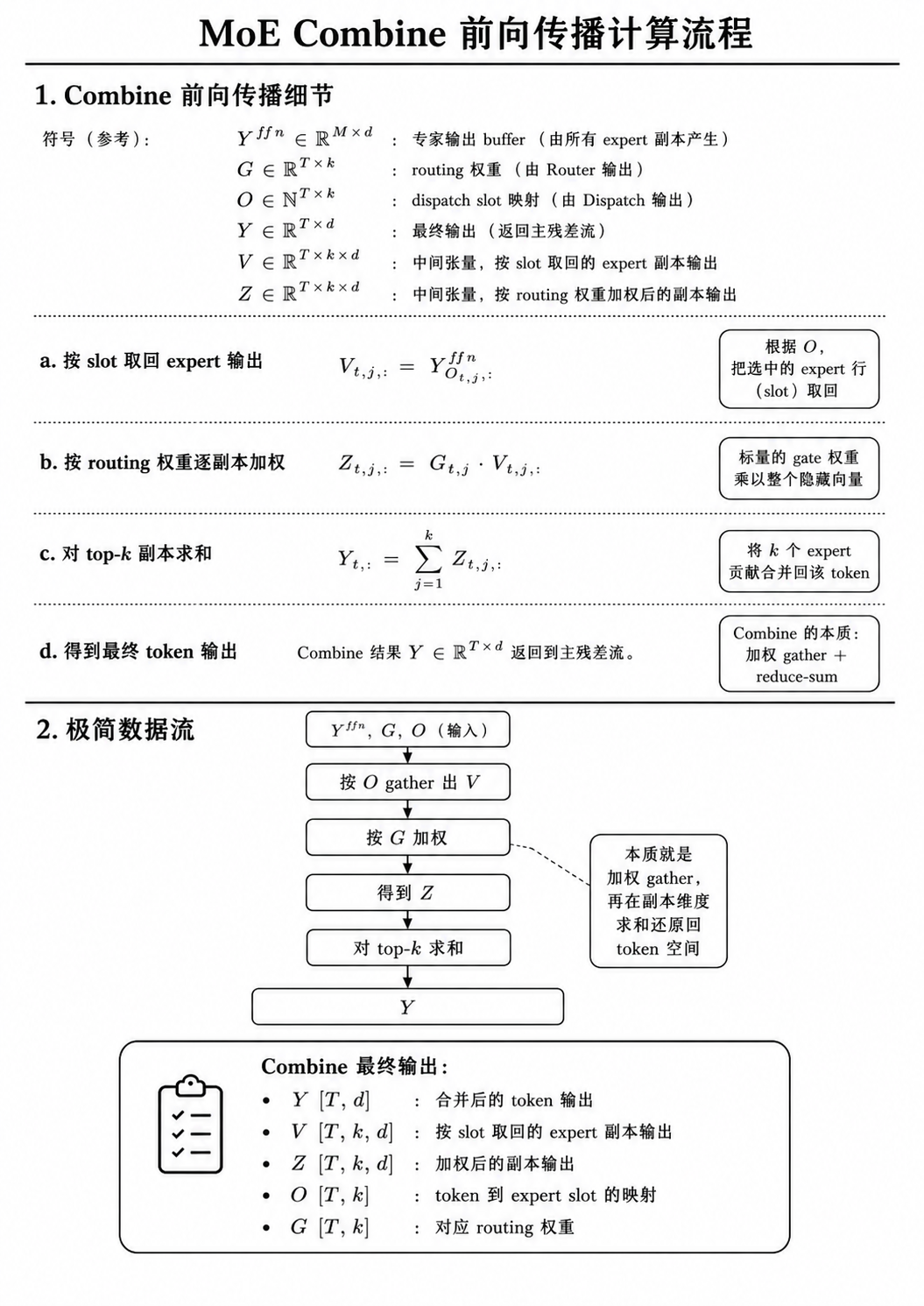
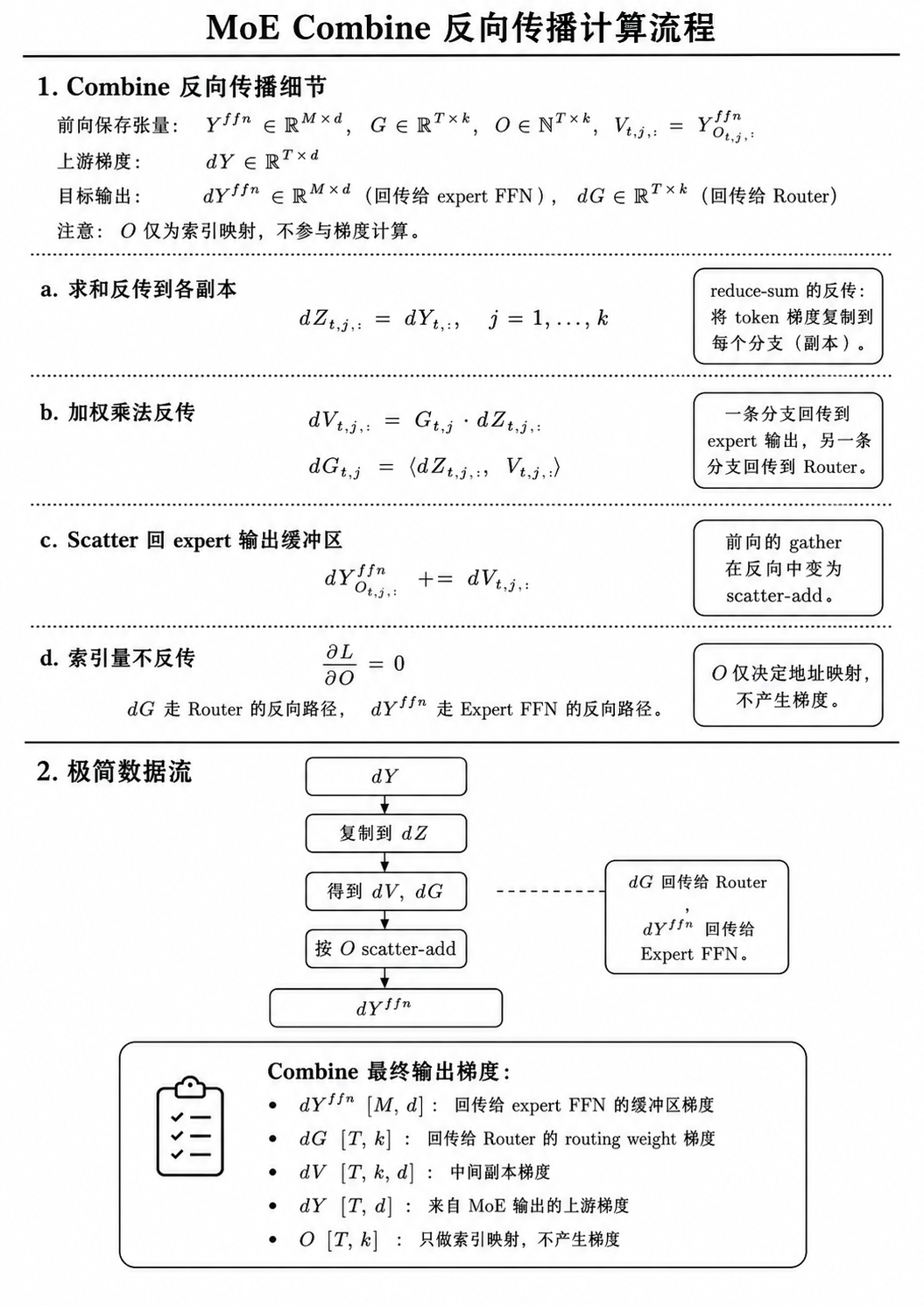
Combine
Combine 把各 expert 的输出按路由权重聚合,并还原到 token 维度。
MoE softmax
MoE做router的意义是什么?
MoE 做softmax的意义和一般softmax意义类似,都是让logits能被解释为概率。 被解释为概率/加权的几个要求:正数,和为1,尺度一致,
哪里用了softmax?
Router阶段:router求r的时候,可以先做softmax后做topk,也可以先做topk后做softmax。先做topk那就是logits(expert)之间做筛选,后做topk那就是根据加权筛选。
或者二者结合,先做softmax,然后topk,再在被选中的expert内部做一次topk
计算流程的一些insight
我什么东西都喜欢搞点insight,要把复杂的流程压缩成低维表示,要不然脑子容量太小记不住所有事。 moe的计算流程大概就是这几步骤,router-disp-ffn-comb 每一步里infra层面的难点各不相同,router主要是做gemm和topk,难点就是优化topk本身。disp主要做的是通信+计数+地址转换+layout转换。一个是经典的alltoall优化,这个被提的太多反而不用特意说。另一个就是layout的变化。从tokenmajor到expertmajor需要改很多地址和引用,所以实际的kernel这个地方会比较复杂。然后ffn阶段主要问题是负载均衡和shape的异构。最后comb阶段一个是layout的转换,从expertmajor到tokenmajor,另一个是做backward的时候它的上游有两个一个是router一个是expert。